Introduction
The purpose of this lab is to be introduced to the relativity new object-based classification scheme. This was done through the eCognition software. This software allows for remotely sensed images to be segmented into homogeneous spatial and spectral regions (objects), training samples to be taken from these regions to train random forest and support vector machines classifiers and execute the classificaion using the previously stated classifiers.
Methods
The first step in this lab was to become familiar with the eCognition software itself. An Erdas Imagine was brought into the software. The image was then given a 4,3,2 false color band combination to help delineate different land cover types. After displaying the image in a 4,3,2 band combination, the next step of the lab was segment the image. For this lab the multiresolution segmentation algorithm was used as it helps delineate different objects at different scales. The scale parameter was set at 9 and the shape and compactness weights were set at 0.3 and 0.5 respectively.
The segemation process was then run resulting in the following image (fig. 1).
 |
| Figure 1. Segmented image using the multiresolution segmentation algorthim with a scale factor of 9. |
After the image was segmented, training samples were collected for the objects in image to train the classifiers that would be applied to image later. For this classification six land cover/land use (LULC) classes were created. They were agriculture, bare soil, forest, green vegition/shrub, urban and water. After reviewing the image and consulting google earth, different objects in the image were assigned different LULC classifications to be used as training samples for the classifiers (fig. 2). Each class was given at least 15 training samples throughout the image.
 |
| Figure 2. A segment of the image were a portion of the training samples for the LULC classes can be seen. |
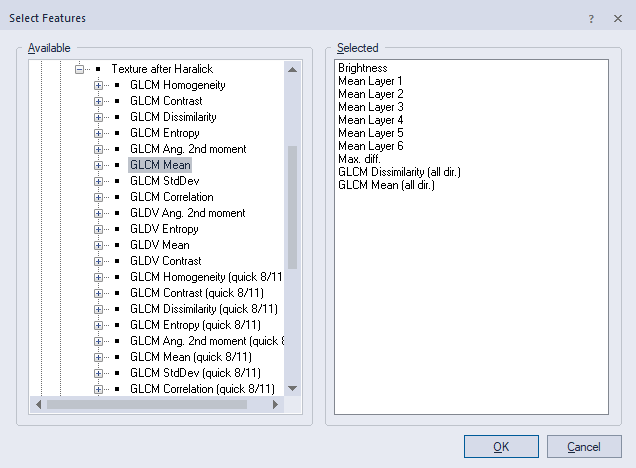
Once all the training samples were collected, the next step was to create a random forest classifier to classify the image. The parameters for the randoom forest classification can be seen below (fig. 3). Features to be included in the classification were the Max Difference between each of the bands, the Max Difference, Gray-Level Co-Occurrence Matrix (GLCM) Dissimilarity, and the GLCM mean (fig. 4). All of this information was contained within a process tree to automize the process of classification (fig. 5).
 |
| Figure 3. Parameters for the random forest classification. |
 |
| Figure 4. Features selected for the random forest classification. |
 |
| Figure 5. Process Tree used to run the random forest classification. |
Results
The process tree was then run createing a random forest LULC classification for the original image (fig. 6).
 |
| Figure 6. Random forest classified image for the Eau Claire/Chippewa Falls area. |
The next section of the lab was to complete a support vector machine classification. This was done by using the same process tree but changing the classification type from random forest to support vector machines. Once this was completed the two different classified images were brought into ArcMap so that they could be compared side-by-side (fig. 7).
 |
| Figure 7. The random forest and support vector machine classified images |
Following the classification of the Eau Claire/Chippewa Falls area, a similar process was used to classify a UAS image collected with the city of Eau Claire using the random forest algorithm (fig. 8).
 |
| Figure 8. UAS image classified using the random forest algorithm. |
Sources
Landsat images are from the Earth Resources Observations and Science Center, United States Geological Survey
UAS image is from UWEC Geography & Anthropology UAS Center.







{kind=link}
No comments:
Post a Comment